
С Ozon.ru мы сотрудничаем не первый год, и уже рассказывали о первой версии генератора рекламных кампаний, разработанной в 2015 году. В этом материале речь будет об автоматизированном подборе низкоконкурентных релевантных ключевых фраз с хорошей частотностью, позволяющих выполнить KPI по ROI.
Задача
Перед подразделением разработки индивидуальных инструментов автоматизации eLama.ru поставили задачу автоматизировать сбор семантики для категории детских товаров интернет-гипермаркета Ozon.ru. При этом нужно было отобрать фразы, которые бы обеспечили выполнение KPI по ROI контекстной рекламы категории.
Специфика тематики
В тематике детских товаров есть несколько особенностей. Во-первых, категория содержит огромное количество наименований товаров (более 70 тысяч товаров). А во-вторых, названия товаров этой категории зачастую довольно специфические. Например, грузовик-погрузчик без приставки «игрушечный» будет нерелевантным. А некоторые характеристики товаров могут, напротив, не иметь значения, например, для товара с названием «игрушка-пылесос с вишенками» совсем не важно, что на нем изображено, поскольку пользователи не ищут игрушечный пылесос именно с вишенками.
Генерировать и управлять
Генерация и управление ставками — это процессы, только на первый взгляд несвязанные. Генератор создал кампанию, ее загружают в рекламную систему, а дальше уже система управления ставками (бид-менеджер, оптимизатор конверсии, автоматическая стратегия или любая другая) применяет алгоритмы и корректирует ставки.
Но дело в том, что какие бы алгоритмы не работали, бид-менеджеру нужно набрать достаточно статистики, чтобы строить точные прогнозы. Поэтому чем больше семантики сгенерировано, тем больше придется потратить средств на накопление достоверной статистики. И, соответственно, тем ниже показатели эффективности — CPA, ДРР и чистая прибыль. Особенно актуально это на старте — в процессе обучения системы управления ставками. Такую задачу можно решить сегментацией или кластеризацией низкочастотных фраз по посадочным страницам/типам генерации/вендорам.
Методика
Создание больших рекламных кампаний осложнено постоянной нехваткой сразу двух ресурсов: баллов API Яндекс. Директа, чтобы всё это загрузить, и денег, чтобы всё это потом протестировать. Поэтому при генерации важно расставлять приоритеты — какие полученные ключевые фразы загружать и тестировать сначала, а что можно и потом. В процессе накопления данных мы выявили закономерности, определяющие, как зависит конверсия от типа фразы.
Какие фразы загружать в первую очередь
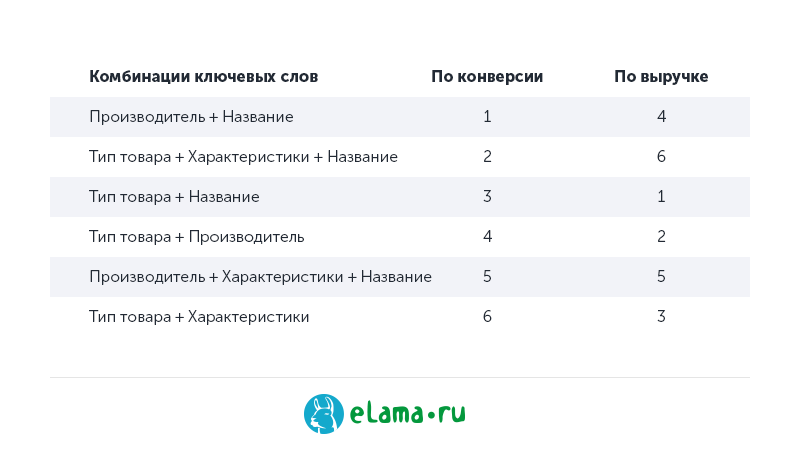
Как правило, не все сгенерированные ключевые фразы показывают одинаковую эффективность. Для примера, при генерации кампаний для интернет-магазинов разные комбинации из свойств товара показывают разный результат.
Например, в наших кампаниях комбинации «Производитель + Название» и «Тип-товара + Характеристики + Название» показывали более высокую конверсию, а ключевые слова с комбинациями «Тип товара + Название» и «Тип товара + Производитель» приносили больше выручки. Мы составили рейтинги комбинаций свойств товаров и по нему распределяли приоритеты загрузки: фразы с более высокими приоритетом загружали в первую очередь.
Как избежать попадания нецелевых ключевых фраз в кампанию
При генерации семантики из фида бывает, что ключевые фразы оказываются нерелевантными или неэффективными. Чтобы определить это на старте, до того, как будут потрачены деньги на рекламу по этой фразе, все двухсловные и трехсловные высокочастотные фразы дополнительно проверяются по вложенной семантике:
Релевантность запроса определяется путем сравнения лемматизированного запроса и лемматизированных же текстов, относящихся к данному товару (название, описание и т. д.). Если в текстах встречается такой набор лемм, то запрос считается релевантным.
Принадлежность к целевым запросам определяется по наличию таких слов как «цена», «купить», «стоимость», «магазин» и других слов, актуальных для конкретной тематики.
Даже если все слова ключевой фразы присутствуют в описании товара, это еще не означает, что запрос целевой. Особенно актуально для высокочастотных фраз и фраз, состоящих из 2−3-х слов. Например, есть товар «Игрушечный автомобиль». В качестве Типа товара система выделяет существительное из названия «автомобиль», отправляет его на проработку в Wordstat. Среди ключевых фраз получаем такие, как «Автомобиль купить», «Автомобиль в Москве». Человеку понятно, что такой запрос нерелеватен в контексте категории «Игрушки». Системе же нужны метрики. Тут и помогает метрика «Доля релеватных подзапросов».
- Запрашиваем у Wordstat’а поисковые запросы, вложенные в проверяемую фразу.
- Определяем их принадлежность к целевым и/или релевантным.
- Считаем долю показов по целевым и релевантным запросам.
- Если полученная доля ниже установленной в настройках генератора, проверяемой фразе будет понижен приоритет, и она будет загружаться и тестироваться в последнюю очередь и с пониженной ставкой.
Подбор синонимов
Принято считать, что поисковая система самостоятельно исправляет опечатки в известных брендах. На практике это далеко не всегда так. Рассмотрим известный многим родителям бренд Baby Born. Если изучить Wordstat и поисковую выдачу Яндекса, то выяснится, что есть как минимум четыре разных варианта написания этого бренда.
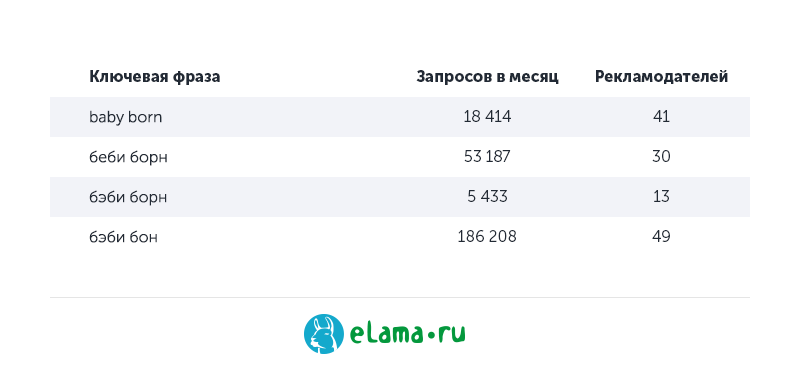
Синонимы распространены и в других характеристиках товара, но в каждой тематике они будут свои. Например, для ноутбуков синонимами могут быть «диагональ 20», «большая диагональ», «большой экран», «20 дюймов». Но для смартфонов, очевидно, такие синонимы неприменимы. Таким образом, по не самым очевидным отдельным вариантам написания бренда (например, бэби борн) конкуренция может быть в
Этот модуль также участвует при сопоставлении фраз с описанием товара, которые мы получали из Wordstat. Например, мы отправили в Wordstat запрос «ноутбук» и получили вариант фразы «ноутбук с большим экраном». Она может быть соотнесена с товаром, если в словаре указано подобное соответствие.
В рамках этого модуля мы также решили задачу подмены «узких» характеристик на их более «широкие» синонимы. Например, как словосочетание «подгузник до 3 кг» соотнести с «подгузник для новорожденных». Сначала работали с алгоритмом, который уравнял «до 3 кг» и «для новорожденных». Однако в таком случае к фразам «игрушки для новорожденных» стали добавляться запросы вроде «игрушки до 3 кг». После этого мы ввели два типа синонимов:

Опять же ограничения синонимов категорией снижает вероятность подмены фраз нецелевыми синонимами, как это сейчас происходит в Директе.
Собирая синонимы, мы работаем по такому алгоритму:
- Анализируется правая колонка Wordstat’а по базовым запросам.
- На основании полученных из правой колонки данных проводится мозговой штурм с привлечением людей, хорошо знакомых с данной тематикой. Такой «ручной» способ до сих пор является одним из самых надежных, поскольку автоматика с такими задачами пока справляется плохо, но мы над этим работаем.
В планах — работа по пополнению словаря синонимов. Так, один из признаков того, что слова являются синонимами, — это слова, которые встречаются с ними. Например, есть два синонима: «спортивные штаны» и «спортивные брюки». Судя по подзапросам, у них много общих слов: мужские, женские, адидас, зимние, размеры, теплые. Мы уверены, что можно выявлять синонимы, просчитывая частотность и количество общих фраз.
Результаты
Совмещая стандартные и сложные лингвистические правила, а также собственные алгоритмы, с помощью которых нам удавалось заранее проанализировать потенциальную конверсионность запросов, мы смогли обеспечить Ozon.ru качественный недорогой трафик и перевыполнить KPI по ROI в поисковых кампаниях на 30%.
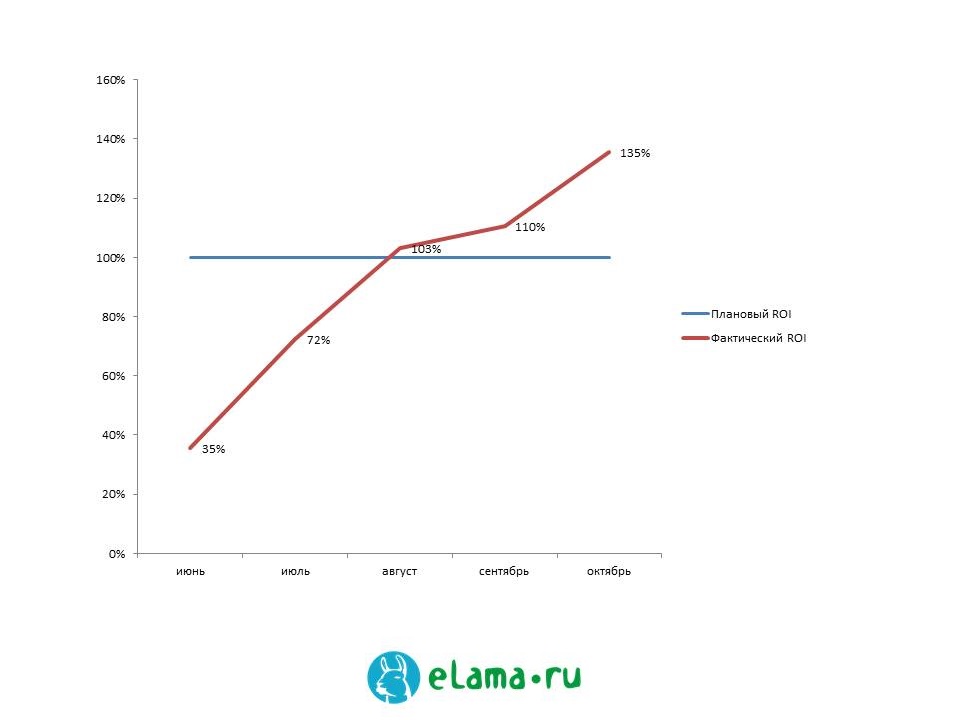
В качестве подтверждения удовлетворенности клиента мы можем отметить, что Ozon.ru передал нам для работы еще две товарные категории.
Благодарим продакт-менеджера eLama.ru Олега Егорова за помощь в подготовке материала.










